
Tools that test code for common vulnerabilities such as OWASP Top Ten fall today in three categories of AST (Application Security Testing) tools: SAST (static code scanning), DAST (dynamic app scan), and IAST (dynamic code scanning). Consequently, there are not a few but a lot of tools, especially in SAST and DAST areas, both commercial as well as open-source.
There are a lot of functional aspects (e.g. coverage of certain programming languages or frameworks, deployment (SaaS vs. on-premise), integration aspects, and so on) that you may have to take into consideration when you evaluate whether a tool is suitable for your company or not.
It gets a bit more complicated when we want to measure non-functional aspects, especially scanning quality.
General Scanning Metrics
First of all, we need to distinguish following the four test outcomes on which we can build respective metrics:
- False Positives (FP): Tools finding that is no vulnerability (bad)
- True Positive (TP): Tool finding that is a valid vulnerability (good)
- False Negative (FN): Valid vulnerability not found be the tool (bad)
- True Negative (TN): Invalid vulnerability not found be the tool (good)
In short: “True” is generally a good outcome, and “positives” (FP and TP) are the ones that we can measure via the false positive rate (FPR) and the true positive rate (TPR). What is missing is good test data that we can use to measure the scan quality of these tools.
The OWASP Benchmark
The OWASP Benchmark Project started in 2015 to provide exactly this. The first major version (v1.1) consists of more than 21,000 test cases that were then reduced to 2,000 one year later (v1.2).
The Benchmark project then scanned these tests with a number of SAST, DAST, and IAST tools. The names of these tools are known, but specific scores (I suppose for legal reasons) are only published for the OSS tools that had been tested. The following graph shows the results as a combination of their TPR and FPR scores which results in the so-called Benchmark Accuracy Score (I will just call it the “score” here):

Basically, the best outcome for a tool would be to end up in the left upper corner (no false positives and 100% true positives). Which makes a lot of sense, since false positives cost a lot of time to validate and reduce the acceptance of a tool.
Here are some interesting findings that we get from this data:
- DAST tools are only able to find a small percentage of vulnerabilities, (e.g. security header) but do a quite good job here.
- SAST tools are generally able to find significantly more vulnerabilities than DAST.
- The more vulnerabilities a SAST tool finds the more false positives it generally finds as well.
- There are a lot of static code analysis tools (like PMD or FindBugs without FindbugSecPlugin) that are useless for security.
Although the latest release is now more than three years old, the Benchmark is still be used, especially by many tool vendors to advertise their products. There are a few aspects of the Benchmark that should be taken into account here:
Problem 1: Different Benchmark Versions
This is clearly not the biggest problem, but worth mentioning: The tools shown on the Benchmark results above are scored against different versions of the Benchmark, some with v1.1 and others (especially the commercial ones) with v1.2.
This makes comparisons of results of course problematic, especially since the Benchmark releases do differ a lot, at least in terms of their test cases (21,000 vs. 2,000).
Problem 2: Limited Test Coverage
The Benchmark has certain limitations that we should be aware of:
- The test cases are completely written Java servlets. No other languages are covers which are especially problematic for SAST and IAST.
- The test cases are based on plain Java – no APIs or frameworks (e.g. JSF, Spring or Hibernate) are covered.
- Only a number of implementation vulnerabilities are covered (command injection, weak crypto, XSS, SQLi, LDAPi, Path Traversal, and XPath Injection mostly). A lot of problems like insecure or missing validation, insecure configuration, XEE, insecure deserialization, etc. are not covered.
- There are a number of potential vulnerabilities such as insecure or missing authentication, access controls or business logic that we will hardly be able to cover with generic test cases like these or AST tools in general.
In other words: Even with a score of 100%, a tool would more or less only cover a baseline for DAST and Java-based SAST. This does not only mean that the Benchmark is limited. I’m really sure that AST tools will not be able to detect all (or most) vulnerabilities, at least not in the near future. This makes such Benchmarks in general limited of nature.
Problem 3: Tools adapt to the Benchmark
Since all test cases of the Benchmark had been made public, tool authors/vendors can use them to tune their tools.
We can see this when we look at the results of Findbug Security Plugin, which started with a score of just 11,65% with version 1.4.0 and reached an impressive score of 39,1% (23% is commercial average) with version 1.4.6:
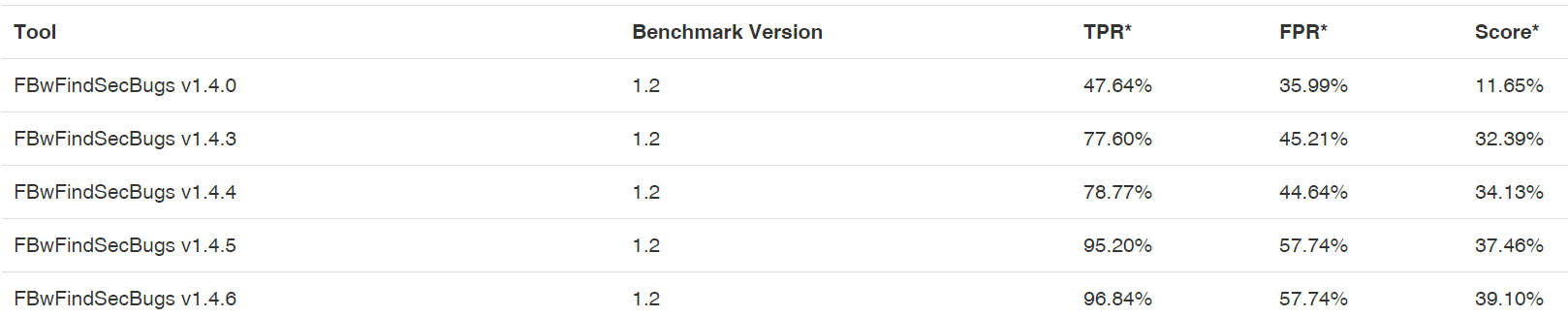
So it’s pretty clear, that the authors tuned the Findbug Security Plugin against the Benchmark. The same goes of course for commercial tool vendors. We do in fact see the Benchmark used for marketing purposes a lot. Being good at the Benchmark does not necessarily mean that vulnerability detection in actual web apps and services has been improved though.
Conclusion
Does this mean that the Benchmark is bad? Of course not! The OWASP Benchmark is, in fact, a great project that helps tools authors to improve their tools and which helped us a lot to get a better understanding of the limitations of AST tools in general and differences of tool categories (SAST, DAST, IAST) in respect of detection capability.
The Benchmark is, however, limited in respect of test coverage and can be misleading, especially since vendors/authors can tune their tools to get a better score.
Therefore, be susceptible when a vendor announces to archive a fantastic Benchmark score in their latest release!
Here are some tips that may help you in case you want (or have) to evaluate tools for your company, project, or team:
- Use SATEC by WASC as a basis for functional requirements (old but still with a lot of good points in it). Here is another useful document. Although by a vendor it has a lot of valid aspects in it that may help you.
- Use your own test code for measuring scan quality:
- After shortlisting a few tools, run a POC or pilot and test them against test applications that are based on your technology stacks and integrate own common vulnerabilities into the code and configuration that you would expect to find. That may cause some work but it will be worth it.
- In addition, test them against releases of your applications with known vulnerabilities (e.g. pentest findings from the past) in it.
- Consider the general limitations of these tools. Do not rely on them but use them only as a safety net, enhance them with your own rules (if the tool supports this) and combine them with your own dynamic and static tests (e.g. Git hooks that blacklist insecure functions or configurations).